




Results 1 to 3 of 3
Threaded View


-
18th Jan 2017, 01:07 PM#1



 OP
OP white hat seo
white hat seo

seo Search Engine Optimization
its organic search results
white hat seo means following the Google Rules and Regulation & Google guidlinesbabubala Reviewed by babubala on . white hat seo https://dc8hdnsmzapvm.cloudfront.net/assets/images/beginners/banner-chapter-4.png seo Search Engine Optimization its organic search results white hat seo means following the Google Rules and Regulation & Google guidlines Rating: 5Last edited by Kevin; 19th Jan 2017 at 07:39 PM.

 Reply With Quote
Reply With QuoteSponsored Links
Thread Information
Users Browsing this Thread
There are currently 1 users browsing this thread. (0 members and 1 guests)


 Staff Online
Staff Online
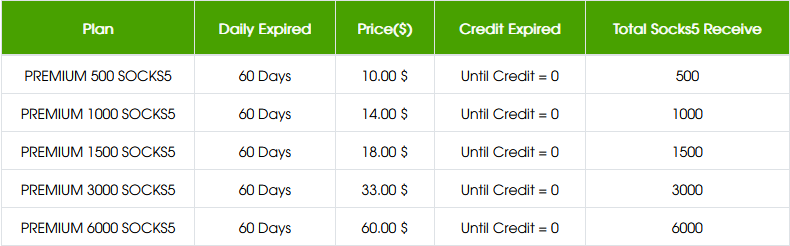
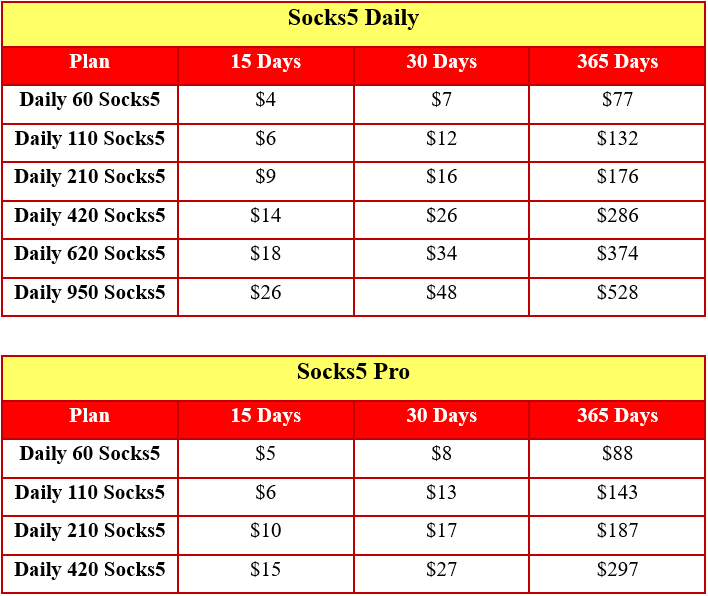
Shopsocks5.com - Service Socks5...
ShopSocks5.com | Fast Residential SOCKS5 Proxies...